Using RAG in Rowboat
Rowboat provides multiple ways to enhance your agents’ context with Retrieval-Augmented Generation (RAG). This guide will help you set up and use each RAG feature.RAG is called “Data” on the build view in the Rowboat UI.
Types of RAG
| RAG Type | Description | Configuration Required |
|---|---|---|
| Text RAG | Process and reason over text content directly | No configuration needed |
| File Uploads | Upload PDF files directly from your device | No configuration needed |
| URL Scraping | Scrape content from web URLs using Firecrawl | Requires API key setup |
URL Scraping does not require any setup in the managed version of Rowboat.
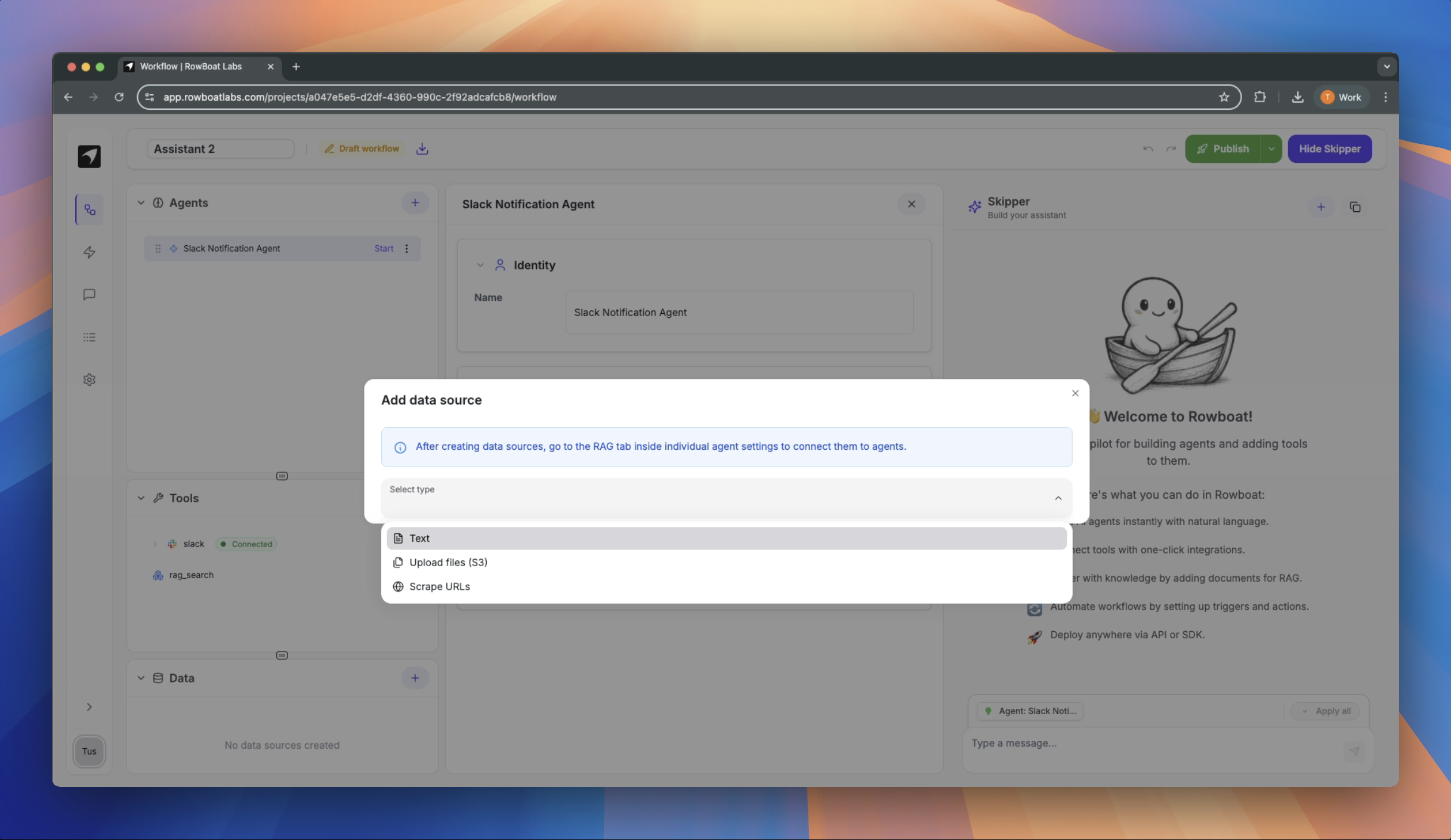
RAG Features
1. Text RAG
Process and reason over text content directly2. File Uploads
- Upload PDF files directly from your device
- Open Source Version: Files are stored locally on your machine
- Managed Version: Files are stored in cloud S3 storage
- Files are parsed using OpenAI by default
You can also use Google’s Gemini model for parsing as it is better at parsing larger files.